从单体到云原生 互联网数据服务的分布式架构演进之路
在数据爆炸式增长和业务需求日益复杂的背景下,互联网公司的数据服务架构经历了一场深刻的演进。这场演进不仅是技术上的革新,更是对高可用、高并发、可扩展性追求的集中体现。其路径大致可分为四个关键阶段:单体架构、垂直拆分、服务化与微服务,以及云原生架构。
第一阶段是单体架构。在互联网初期,业务相对简单,用户量有限,大多数公司将应用、数据库和文件存储等所有功能模块集中部署在一个单一的服务进程中。例如,早期的门户网站或论坛系统,使用一个大型的数据库(如MySQL)和一套应用代码(如LAMP栈)即可支撑。这种架构开发部署简单,但存在明显瓶颈:所有模块耦合紧密,牵一发而动全身;随着用户增长,单一数据库和服务器成为性能瓶颈,无法水平扩展;任何模块的故障都可能导致整个服务宕机。
当单台服务器的性能极限被触及,架构演进便进入了垂直拆分阶段。公司根据业务功能将庞大的单体应用拆分成多个独立的、功能相对集中的子系统。例如,将用户中心、商品服务、订单服务、支付服务等分离,每个子系统使用独立的服务器和数据库。此举有效降低了耦合度,不同团队可以并行开发。通过为访问量大的服务(如核心数据查询)配置更强的硬件,实现了“纵向扩展”。拆分后子系统间的交互变成了跨进程的网络调用,带来了接口定义、通信可靠性和数据一致性等新的挑战。公共功能(如用户认证、缓存)的重复建设也造成了资源浪费。
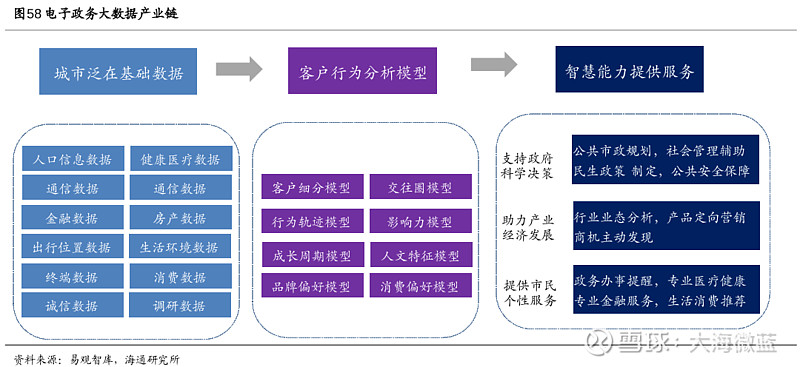
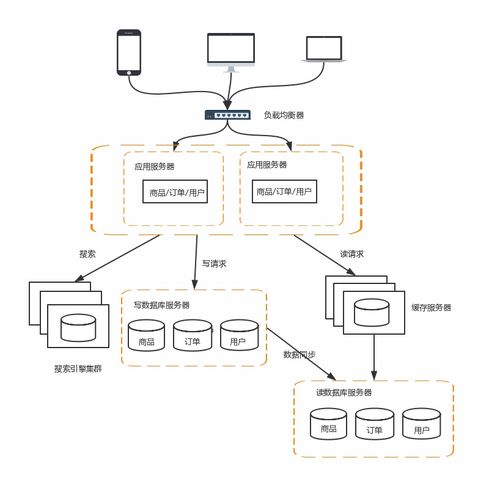
为解决上述问题,服务化与微服务架构应运而生。这一阶段的核心是将可复用的业务能力沉淀为独立的、细粒度的服务,并通过轻量级的通信机制(如HTTP/REST或RPC)进行协作。服务注册与发现(如ZooKeeper, Eureka)、配置中心、API网关、分布式追踪等组件构成了完整的服务治理体系。对于数据服务而言,这一阶段的标志性变化是数据库的深度拆分。单一数据库被拆分为多个专业数据库,例如,用户关系数据用图数据库,日志数据用时序数据库,商品信息用文档数据库,并广泛引入缓存(如Redis)、消息队列(如Kafka)和搜索引擎(如Elasticsearch)来解耦流程、提升性能。数据服务本身也从一个庞大的“数据层”演变为一系列独立的“数据微服务”,如用户画像服务、实时推荐服务、风控数据服务等,各自管理其数据存储与计算逻辑。
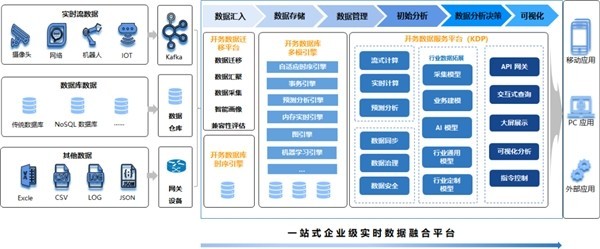
当前,架构演进的前沿已步入云原生架构阶段。它以容器化(Docker)、动态编排(Kubernetes)、服务网格(如Istio)和声明式API为基础,旨在构建弹性、可观测、可管理且松耦合的系统。对于互联网数据服务,这意味着:
- 计算存储分离与Serverless化:数据计算(如Spark/Flink任务)与存储(如对象存储S3、云数据库)彻底解耦,数据湖/仓理念普及。数据处理任务可以按需启动,以Serverless函数的方式运行,实现极致的资源弹性。
- 混合部署与多云策略:数据服务可以灵活部署在混合云或多云环境,利用不同云厂商的优势服务,同时避免供应商锁定,并满足数据本地化等合规要求。
- 数据智能与实时化:架构支撑流批一体数据处理,能够应对海量实时数据流(如IoT、用户行为),并集成机器学习平台,使得数据服务不仅能“存”和“查”,更能实时“预测”与“决策”,例如实时反欺诈、动态定价等。
- 可观测性与自动化运维:通过完善的Metrics、Logging、Tracing体系,实现对分布式数据链路全栈的监控与诊断,并结合AIOps实现故障自愈与性能调优的自动化。
纵观这场演进,其驱动力始终来自业务需求与技术创新的双轮驱动。从紧耦合到松耦合,从静态扩展到动态弹性,从资源中心化到能力服务化,互联网数据服务的架构演进之路,本质是一条不断提升系统韧性、开发效率与业务响应速度的探索之路。随着算力网络、边缘计算和异构计算的发展,数据服务的架构必将朝着更智能、更分布、更融合的方向继续演进。
如若转载,请注明出处:http://www.hulgljd.com/product/8.html
更新时间:2026-06-19 11:08:56